IBM C2090-930 Exam Questions
Questions for the C2090-930 were updated on : Apr 22 ,2025
Page 1 out of 4. Viewing questions 1-15 out of 60
Question 1
You need to export data using IBM SPSS Modeler Professional.
Which two nodes should be used to accomplish this task? (Choose two.)
- A. Database B.Select C.Flat File D.Filter
Answer:
A,C
Explanation:
Reference:
ftp://public.dhe.ibm.com/software/analytics/spss/documentation/modeler/16.0/en/modeler_nodes
_general.pdf
Question 2
You have two data sets. One data set contains customer name and age information along with a
customer ID. The second data set contains the customer ID along with address information. There are
no addresses which do not belong to a customer, there are customers which have no address, and
there are customers which have multiple addresses.
Which type of join will display all customers who have no recorded address?
- A. Inner join B.Outer join C.Partial outer join D.Anti-join
Answer:
C
Question 3
What is the primary purpose of the Partition node in a modeling effort?
- A. Divide the data into training and testing data. B.Increase the proportion of under-represented subgroups within the data. C.Decrease the proportion of an over-represented subgroup within the data. D.Allow for equal sampling across subgroups within the data.
Answer:
C
Explanation:
Reference:
ftp://public.dhe.ibm.com/software/analytics/spss/documentation/modeler/16.0/en/modeler_nodes
_general.pdf
Question 4
You want to calculate the difference between the minimum and maximum values of some of your
data fields.
Which feature or mode of the Aggregate node would allow you to calculate this using a single node?
- A. Aggregate expressions B.Median mode C.Default mode D.Key field grouping
Answer:
B
Explanation:
Reference:
ftp://public.dhe.ibm.com/software/analytics/spss/documentation/modeler/15.0/en/UsersGuide.pdf
Question 5
You have a data set with numeric fields (columns) that contain null values. You want to replace each
of these null values with the value of zero.
Which node will you use to accomplish this task?
- A. Type node B.Filler node C.Filter node D.Binning node
Answer:
C
Question 6
A client has a business goal of increasing units sold by 10 percent.
Which two data mining objectives would be consistent with their business goal? (Choose two.)
- A. Create a profile of customers most likely to default on their account. B.Create a profile of current high value customers' purchasing patterns. C.Reduce marketing costs. D.Determine which products should be grouped together on the shopping Web site.
Answer:
B,C
Question 7
You have a data source which provides many fields needed for data scoring. Some of these fields are
not needed after the scoring is complete for the rest of the stream to operate.
Which node should be used to remove these fields?
- A. Filter node B.Select node C.Sample Node D.Type node
Answer:
B
Question 8
You have a large amount of data from which you want to build a model. Although many of the
records of data are complete, there are substantial amounts of records which contain missing dat
a. The records containing incomplete information should be excluded from analysis.
Which node will exclude the undesired records?
- A. Filler node B.Filter node C.Select node D.Aggregate node
Answer:
C
Question 9
You have optimized four models that do not meet your performance goals. You believe that by
mergingthese models together you would achieve better performance.
Which node would allow you to accomplish this task?
- A. Aggregate node B.Reclassify node C.Regression node D.Ensemble node
Answer:
D
Question 10
Which two statements are true about linear regression? (Choose two.)
- A. The estimation method of coefficient is ordinary least squares. B.Methods for variable entry and removal are Enter Stepwise, Forward, and Backward. C.The calculation of the predictor importance is based on Regression Sum-of-Squares. D.Adjusted R-Squared is not a measure for Goodness-of-Fit.
Answer:
B, C
Explanation:
Reference:
http://www-
01.ibm.com/support/knowledgecenter/SSLVMB_21.0.0/com.ibm.spss.statistics.help/linear_regressi
on_methods.htm
Question 11
You need to determine whether a variable should be removed in the stepwise variable selection
methods in logistic regression.
Which two metrics are used to accomplish this task? (Choose two.)
- A. Wald Statistic B.KS-Statistic C.Likelihood Ratio (LR) Statistic D.Z-Statistic
Answer:
A, D
Question 12
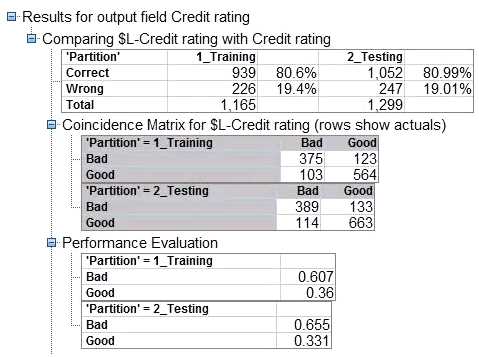
Referring to the exhibit, from which node is the output generated and on which data does it show
greater accuracy?
- A. Statistics, 1_Training B.Statistics, 2_Testing C.Analysis, 1_Training D.Analysis, 2_Testing
Answer:
B
Question 13
How many stages are there in the CRISP-DM process model?
- A. 4 B.6 C.8 D.10
Answer:
C
Question 14
You want to create a Filter node to keep only a subset of the variables used in model building, based
on predictor importance.
Which menu in the model nugget browser provides this functionality?
- A. File B.Preview C.View D.Generate
Answer:
C
Question 15
Which palette contains the Data Audit node?
- A. Output B.Modeling C.Graphs D.Sources
Answer:
A
Explanation:
Reference:
http://www-01.ibm.com/support/knowledgecenter/SS3RA7_17.0.0/clementine/record_ops_nodes.html